左程云课程总结
说明
- 记录一下左程云算法讲课的内容,方便查找
- 左程云:算法
- 基础提升
- 哈希函数与哈希表:大文件限制内存求数字、哈希表与哈希函数性质、布隆过滤器与位图、一致性哈希
- 有序表与并查集:岛屿问题、并查集、KMP
- KMP与Manacher:Manacher算法、窗口内最大值最小值更新结构、单调栈
- 滑动窗口与单调栈:树形DP、Morris遍历、大文件小内存问题
- 二叉树的Morris遍历:大数据题目解题技巧(大文件找中位数、重复数)、位运算(不使用比较进行比较、幂次判断、加减乘除)
- 大数据题目:暴力递归改动态规划(机器人移动,最少的硬币数)
- 技巧
- 中级提升班1:滑动窗口、打表优化、预处理、随机函数位运算
- 中级提升班2、3:递归转dp、遍历、哈希表、业务分析、dp、辅助栈、二叉树套路、右上角查找
- 中级提升班4:业务分析(考虑当前位置)、宏观调度(旋转打印类)
基础提升-哈希函数与哈希表(P40)
哈希函数性质介绍
- 视频:
0:02:40-0:21:00
求大文件中出现次数最多的数(内存限制1G)
- 视频:
0:21:00-0:36:40 - 有一个大文件,里面数的范围是$[0, 2^{32}-1]$,数量为
40亿,内存限制为1G,求出现次数最多的数
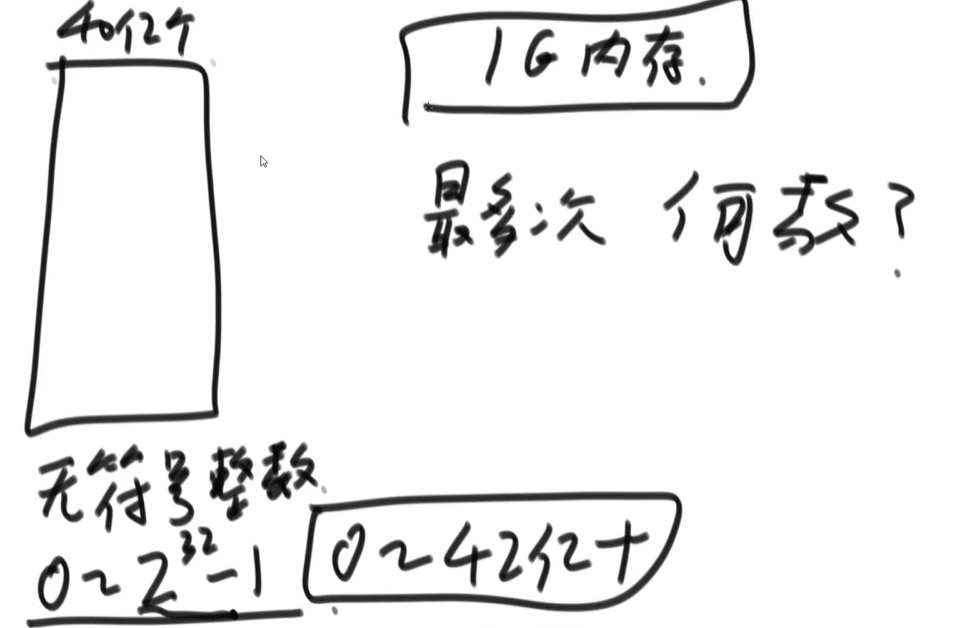
思路1——直接使用哈希表进行统计
- 这种方案不行,会爆内存
- 因为哈希表中一条记录至少
8字节,还不考虑额外开销,当40亿个数都不相同时,所占内存为8字节 * 40亿 = 320亿字节 = 32G(因为$1G = 2^{30}字节\approx10亿$)
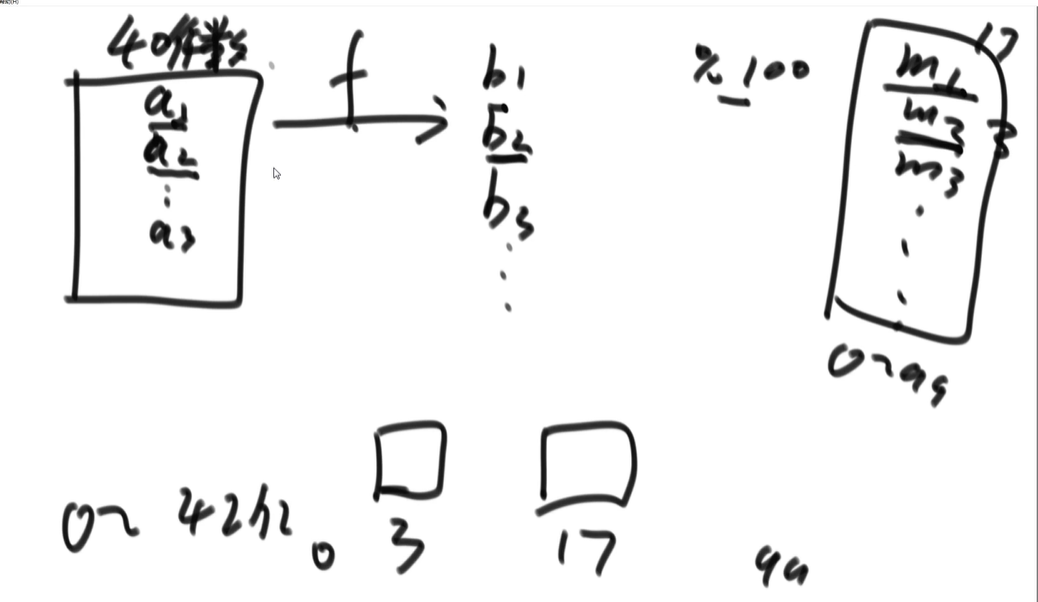
思路2——哈希表改进
- 前置知识
- 哈希表空间的使用只和不同数的种类有关,即假设1出现2次和3出现1w次,所占用的空间一样,都是8字节(不考虑额外开销,key和val都是int)
- 经过哈希函数计算后,数在$[0,S]$均匀分布,那么再模上一个M,最终在$[0,M-1]$均匀分布
- 对文件中的每个数用一个哈希函数计算得到一个结果,然后对一个M取模(此处取M=100),那么每个数会均匀分布在0-99号文件(相同的数会进同一个文件),即0-99号文件中,数的种类接近
- 然后找到每个文件中出现次数最多的那个,合并100个结果,即可找到最终答案
- 由于分成了100个文件,那么每个文件所占用的空间只有
32G/100,符合要求
哈希表性质介绍
- 视频:
0:36:40-0:54:20 - 哈希函数 + 开链法
设计RandomPool结构
- 视频:
0:54:20-1:07:35 - 380. O(1) 时间插入、删除和获取随机元素

思路及代码
- 哈希表+数组或者两个哈希表+数量size
- 哈希表 + 数组:哈希表存
[字符串,下标],数组存[下标,字符串] - 两个哈希表:哈希表1存
[字符串,下标],哈希表2存[下标,字符串],size即为元素个数
- 哈希表 + 数组:哈希表存
- 删除时,和最后一个元素进行交换
- 等概率返回:使用随机生成器
rand()得到0-size-1的数,返回即可
1 | class RandomizedSet { |
布隆过滤器与位图
- 视频:
1:07:35-1:55:40
前置知识
需要一个集合(有增加、查询功能,没有删除功能)
- 如维护一个网址黑名单,存放
url,每个url限制为64字,共100亿条数据 - 如爬虫去重问题:多线程时不想爬取同一个
url
- 如维护一个网址黑名单,存放
直接用
hashset存,内存代价较高,即需要64字节 * 100亿= 6400亿字节 = 640G布隆过滤器:放置在内存,但允许一定的失误率,失误率指不在黑名单,但误报了在里面(通过人为设计,可以降得很低)
位图
位图:每个位置是1 bit,那么长度为100的共占100 * 1/8 字节实现:通过基础类型拼凑实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36/*
* @Author : 955nice
* @Date : 2022-04-15 10:40:48
* @version : 1.0
* @LastEditors : 955nice
* @LastEditTime : 2022-04-15 10:57:41
* @Description : 基础类型实现bitmap
* @FilePath : /code/job/bitmap.cpp
* Talk is cheap, Show me the code
* @refer : None
*/
using namespace std;
int main()
{
int a = 0; // 32bit:4byte * 8bit
int arr[10]; // 320bit:4 byte * 8bit * 10
// arr[0] int 0 ~ 31
// arr[1] int 32 ~ 63
// arr[2] int 64 ~ 95
// 想取得178bit的状态
int i = 178;
int numIndex = 178 / 32;
int bitIndex = 178 % 32;
// 拿到第i位的状态
int s = ((arr[numIndex] >> bitIndex) & 1);
// 将第i位的状态修改为1
arr[numIndex] = arr[numIndex] | (1 << bitIndex);
// 将第i位的状态修改为0
arr[numIndex] = arr[numIndex] & (~(1 << bitIndex));
return 0;
}
布隆过滤器
哈希函数 + 位图
每一个
url使用k个哈希函数进行求值,求得的结果再模以M(位图长度),得到最终结果,将位图中这一位的状态修改为1(假设初始为0)在查询某个
url时,同样使用k个哈希函数进行求值,求得的结果再模以M,得到最终结果,如果和位图中这些位都为1,那么即存在在黑名单中
位图M越大,失误率越低,哈希函数数量k与数据和位图大小有关

计算公式
- 使用前提
- 符合集合查询的要求
- 要求知道
样本量n和失误率p - 注:单样本大小不影响布隆过滤器设计
- 公式1:$m = -\frac{n*lnp}{(ln2)^2}$,计算位图大小,那么假设失误率
p=0.0001,n=100亿,那么占用内存大约为26G - 公式2:$k = ln2\frac{m}{n} \approx 0.7\frac{m}{n}$,计算哈希函数个数,约等于19(向上取整)
- 公式3:$p_{真}=(1-e^{-\frac{n*k_{真}}{m_{真}}})^{k_{真}}$,如果实际内存可以更大,可以算出真实失误率

一致性哈希
- 视频:
1:59:00-2:26:30 - 小林:一致性哈希
基础提升-有序表与并查集(P41)
岛屿数量
- 视频:
0:03:00-0:19:15 - 参考:岛屿问题通解
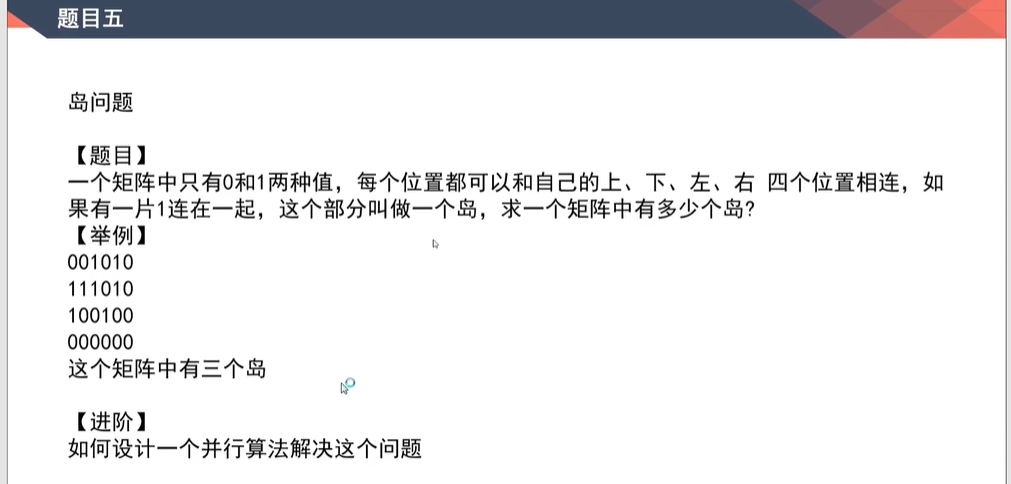
思路及代码
- 标准
bfs感染过程
1 | void bfs(vector<vector<int>>& arr, int m, int n, int i, int j) { |
并查集
- 视频:
0:25:00-1:05:50
思路及代码
- 和视频略有不同,为C++标准版
- 代码为LC1135:最低成本连通所有城市
1 | /* |
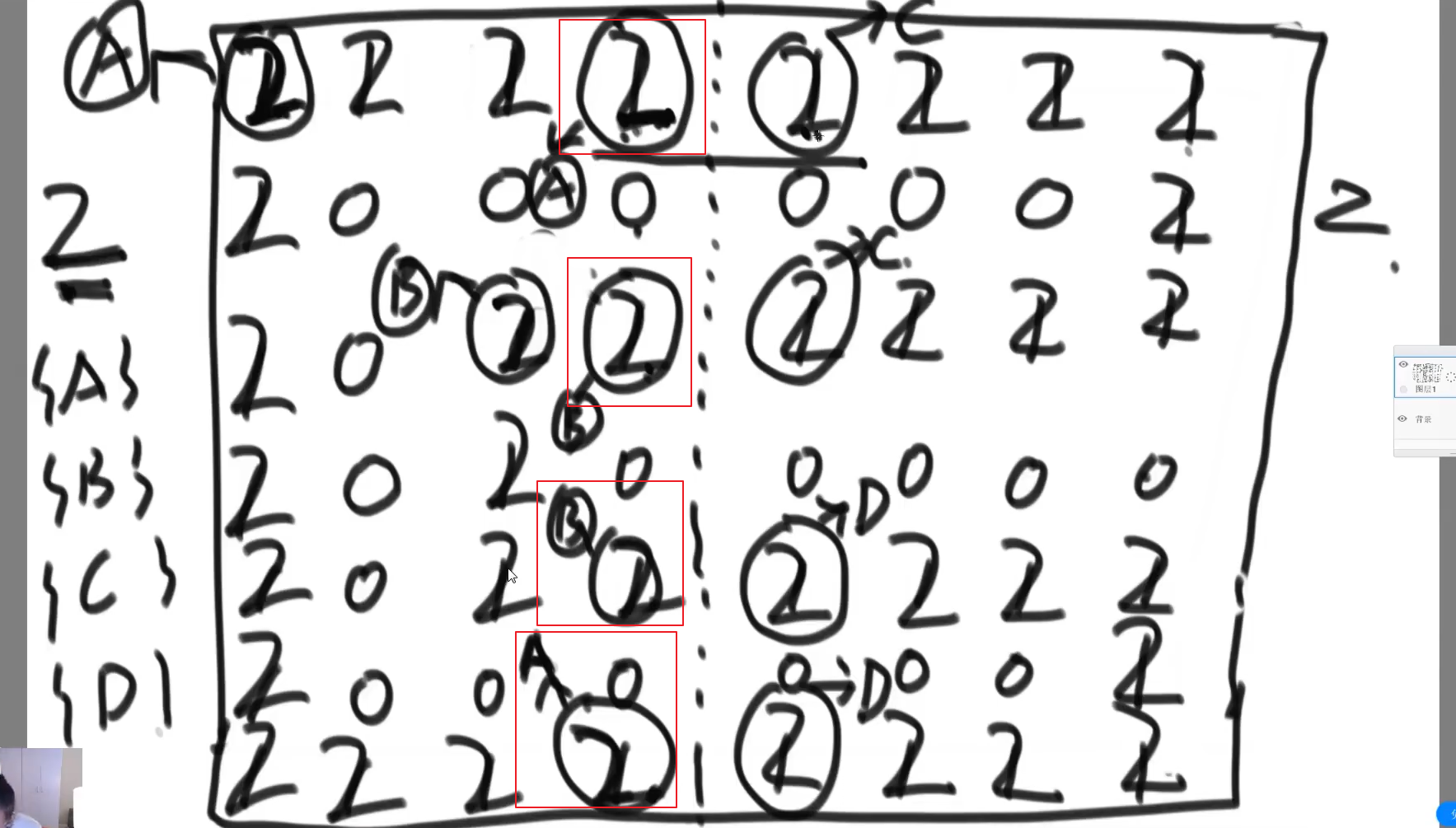
岛进阶(并行算法)
- 二维数组巨大,需要先进行分割计算然后合并结果=>并查集
- 视频:
1:05:50-1:20:40
思路
- 记录切割边界信息(由哪个点感染得到)
KMP
- 视频:
1:28:00-3:15:20
思路及代码
1 | vector<int> getNext(string str2) { |
基础提升-KMP与Manacher(P42)
Manacher
- 视频:
0:02:35-1:40:00
思路及代码
- 详细笔记:Manacher
- 下列代码与笔记略有不同,与视频讲解一致,区别在于一个求长度,一个求真正的串
1 | int maxLcpsLength(string s) { |
窗口内最大值最小值更新结构——双端队列
- 视频:
1:43:45-2:11:10 - 剑指 Offer 59 - I. 滑动窗口的最大值

思路及代码
首先窗口左右边界
L和R只能往右动,左边界永远不要超过右边界求最大值:保证双端队列是单调递减的
如果求最小值:保证双端队列是单调递增的
双端队列
deque放下标(为了获得更多的信息)时间复杂度:每个位置数最多进窗口一次,最多出窗口一次,双端队列的更新总代价为
O(n),一共n个数,所以单次的平均时间复杂度为O(1)
1 | class Solution { |
单调栈*
- 视频:
2:11:10-2:37:05 - 739. 每日温度
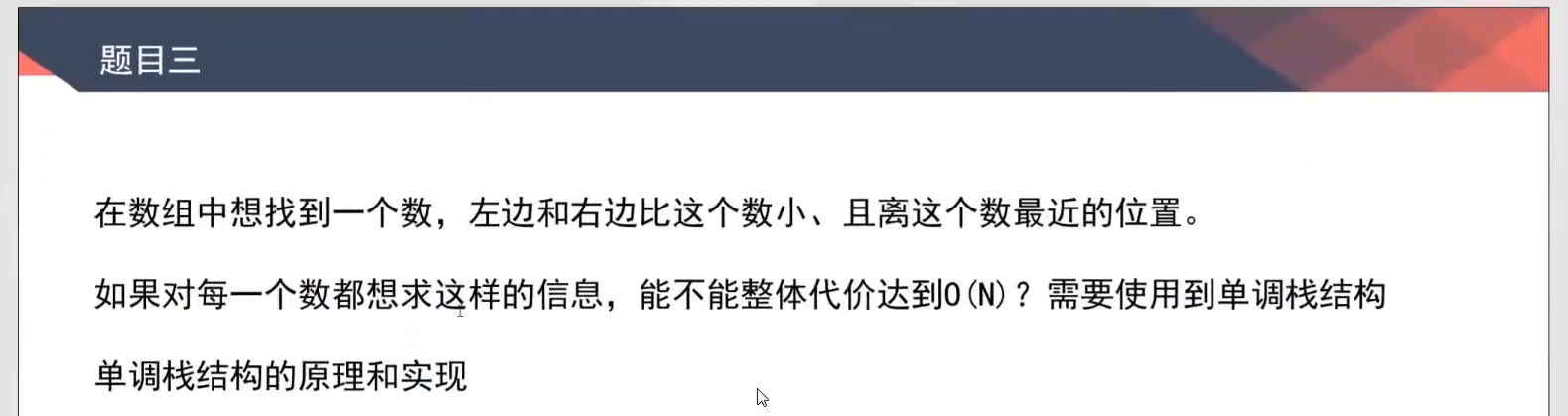
思路及代码
无重复值:求左右比当前位置大的最近位置:单调递减栈
有重复值:单调栈每个元素时一个链表(相同数字串成链表)
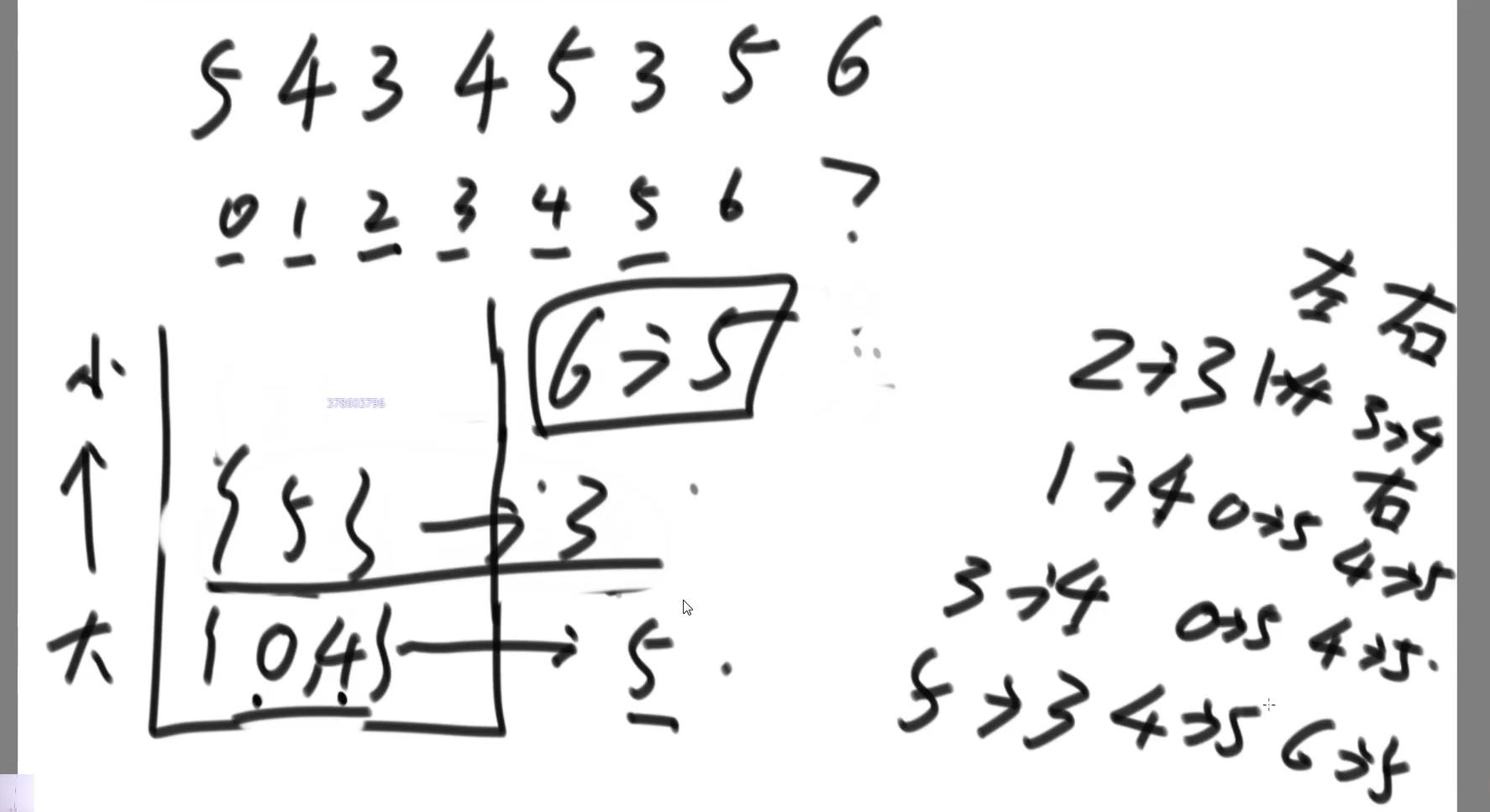
累计和与最小值乘积的最大值——单调栈*
- 视频:
2:37:05-2:47:55 - 数组中元素都为正数,子数组是连续的

思路及代码
- 要点:必须包含i位置的值,且i位置为子数组中的最小值,哪个子数组得到的指标A得到的结果最大
- 单调递增栈实现(即求出每个位置左右两边比当前位置小的范围)
基础提升——滑动窗口与单调栈(P43)
树形DP套路
使用前提

步骤

二叉树节点间的最大距离——树形DP
- 视频:
0:03:05-0:21:35 - 543. 二叉树的直径

思路及代码
考虑以
X为头的数,两种情况- 最长距离和
X有关,即路径经过X - 最长距离和
X无关,即路径在左孩子上或路径在右孩子上
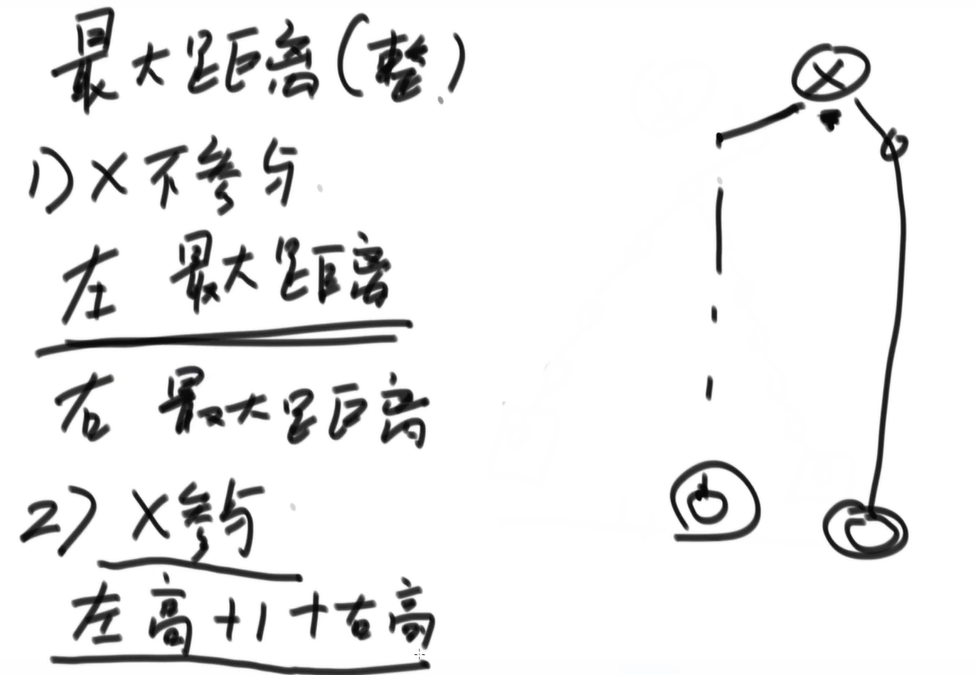
- 最长距离和
1 | /** |
附:全局变量记录法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
int ans = 0;
// 用来判断节点个数
int process(TreeNode* root) {
if (root == nullptr) return 0;
int left = process(root->left);
int right = process(root->right);
ans = max(ans, left + right + 1);
return max(left, right) + 1;
}
public:
int diameterOfBinaryTree(TreeNode* root) {
process(root);
return ans - 1;
}
};
排队最大快乐值
- 视频:
0:21:35-0:35:35 - 派对的最大快乐值

思路及代码
分为两种大情况
- 当前员工X来:那么下层员工都不能来,那么当前的值为X的快乐值 + 下级不来的最大快乐值
- 当前员工不X来:那么下层员工可能来,求max(下级不来的最大快乐值, 下级来的最大快乐值)
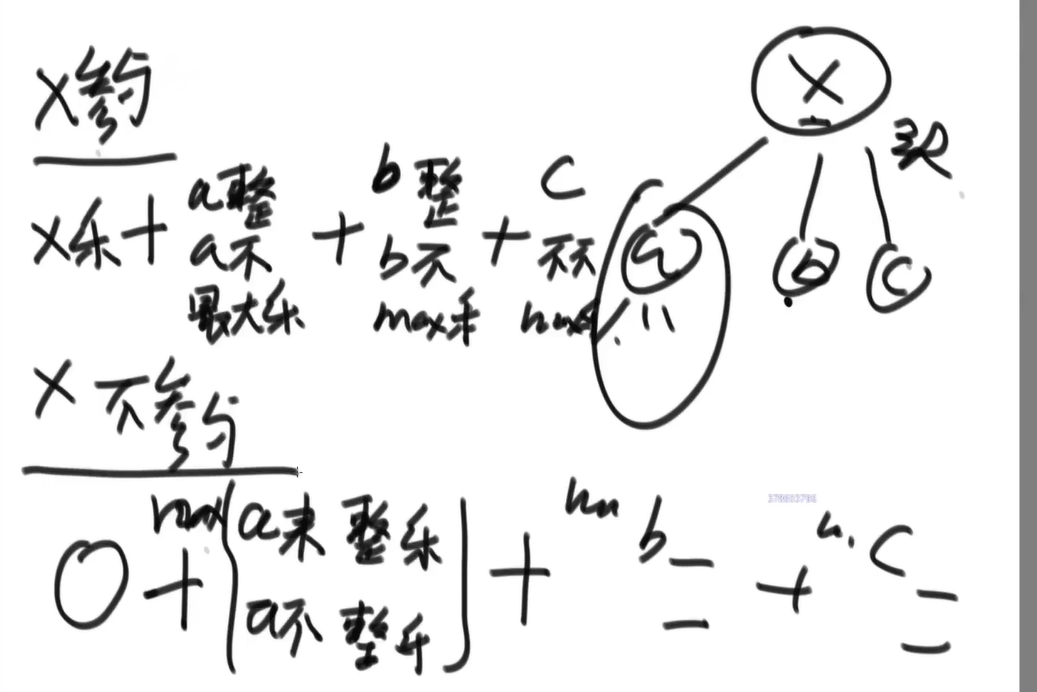
1 |
|
Morris遍历
- 视频:
0:39:25-1:37:40
思路及代码
1 | void Morris(TreeNode* root) { |
树形DP与Morris
- 视频:
1:37:40-1:40:00 - 树形DP:必须做第三次信息的强整合
- Morris:其他情况
大范围数小内存找没出现的数(内存限制1G)——位图
- 视频:
1:44:45-2:05:20
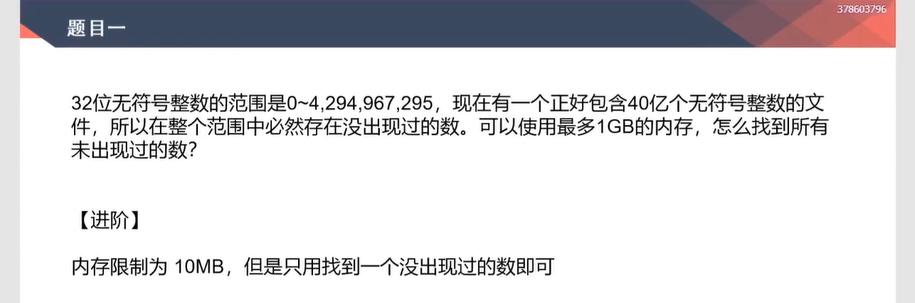
基础:1GB
- 用整形表示位图,那么一个
int为4字节,可以表示32 bit - 数的范围为$2^{32} - 1$,那么需要$2^{32}/8$字节大小的空间(申请$2^{32}$bit大小的数组,一个字节表示8位,共需要512M即可)
进阶1:3KB
- 只有
3 KB内存,求一个没出现的数字 - 首先看,
3 KB内存可以支持开多大的整形数组=>3 KB / 4 = 700+,那么最接近的是512(512 * 4字节=2KB) - 然后将,范围内的数字分成
512份,那么每一份为$2^{32} / 2^9 = 8388608$ - 此时,数组中的每一位表示某个范围内的数出现的次数,如
arr[0]表示0 ~ 8388607出现的次数,依次类推 - 那么对于40亿中的某个数,落在的范围即
x / 8388608,落在哪个位置,就词频++ - 那么范围为0 ~ 42亿,而数字为40亿个,那么必然有某个范围的数不足 8388608个
- 找到某个不足量的位置后,然后继续拆分,直到定位到没出现的数字
进阶2:有限几个变量
- 先对
范围二分(0~42亿),因为只有40亿数,所以必然有一边不足$2^{32} / 2$,对不足的一半继续二分
基础提升——二叉树的Morris遍历(P44)
大数据题目解题技巧

大数据范围找重复URL
- 视频:
0:02:35-0:13:45

基础——哈希函数
- 哈希函数分流:每一个URL算出一个哈希值,然后对m取模,所以一种URL会进一个小文件,然后依次对每个小文件计数,最后汇总
- 布隆过滤器(存在一定误差):边添加边查询
补充——二维堆
- 堆:根据系统配置,分成多个小文件,每个小文件按大根堆组织,然后准备一个总大根堆,里面放每个小文件的
top1,然后依次从总大根堆弹出记录,并更新小文件(假设总大根堆的top1为文件3的top1,那么弹出总大根堆的top1且删除文件3的top1,并将文件3的top2加入总堆,依次类推,直到找到top100)

大范围小内存找出现了两次的数
- 视频:
0:13:45-0:36:25

基础:1GB
哈希函数分流:因为会爆内存(一条记录至少8字节,最坏情况,40亿数都不相同,即320亿字节,大约为32G)位图:用两个位图表示,那么对于$2^{32}$种数,每一个数用两位表示,换算成字节,共需要$2^{32} * 2 / 8$字节,即
1G1
2
3
4
5
6/*
00:表示没出现过
01:表示出现1次
10:表示出现2次
11:表示出现2次以上
*/
进阶:10MB/10KB等——找中位数
- 看给定的内存能支持开辟多大的无符号整形数组,每一位表示一个范围的词频数量
- 对于10MB:10MB/4B,最接近的$2^?$为$2^{20}$,即可以开这么大数组,那么数组每一位表示$2^{32}/2^{20}$大小的数,记录累计词频即可
- 对于10KB:10KB/4B,最接近的$2^?$为$2^{11}$,即可以开这么大数组,那么数组每一位表示$2^{32}/2^{11}$大小的数,记录累计词频即可
- ==视频中每一位表示的范围说的有点问题,大概这个意思就行==
补充题:无序大文件变有序大文件
视频:
0:40:15-1:06:40有一个无序的
10G大文件,每一条记录是一个整数,给定5G内存,要求变成有序文件(保留所有数)
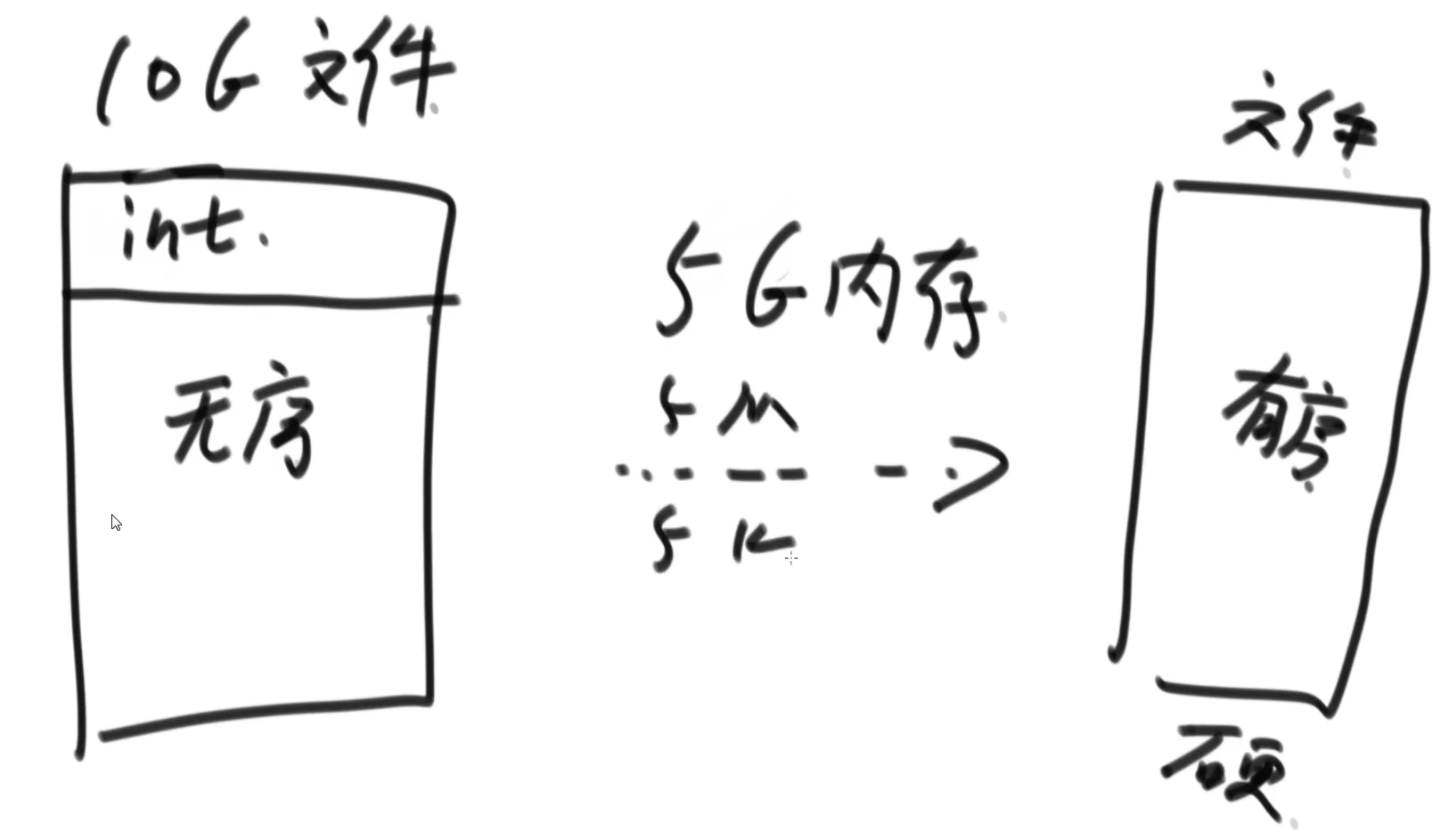
基础:5G内存
- 堆:使用小根堆,小根堆存放某个数及其出现的次数,并根据数的大小进行组织,而不是出现的次数,那么一条记录占用
8字节(可能小根堆组织需要内存,所以可以假设一条记录使用16字节),因为对于5G内存,最多$5GB/16B=2^{28}$条记录,然后将范围等分成$2^{32}/2^{28}=16$份 - 然后从小范围到大范围依次统计出现的情况,并将其按照数的大小及词频添加到最终文件中
位运算——不使用比较比较大小
- 视频:
1:06:40-1:22:45

思路及代码
1 | /* |
位运算——判断是否为2或4的幂次
- 视频:
1:25:55-1:34:15

思路及代码
1 | /* |
位运算——加减乘除
- 视频:
1:34:15-2:18:50
思路及代码
1 | /* |
基础提升——大数据题目(P45)
机器人左右移动——递归转DP
- 视频:
0:02:45-0:59:50 - 题意:给定一个数组,表示机器人可以移动的范围,机器人起始位置为S,可以走K步,想要去到E,问有多少种方法

暴力递归
1 | int process1(int N, int E, int cur, int rest) { |
记忆化搜索
1 | int process2(int N, int E, int cur, int rest, vector<vector<int>>& memo) { |
动态规划
- 画图来帮助改DP
1 | int walkWays3(int N, int E, int S, int K) { |
凑零钱(有重复,只能选一次)
- 视频:
1:05:50-2:03:01 - 题意:给定一个数组,代表硬币的面值(可能有重复,只能选一次),问凑出aim的最少硬币数量,不能凑出,返回-1

暴力递归
1 | int process1(vector<int>& nums, int index, int rest) { |
记忆化搜索
1 | int process2(vector<int>& nums, int index, int rest, vector<vector<int>>& memo) { |
动态规划
1 | int minCoins3(vector<int>& nums, int aim) { |
基础提升——暴力递归(P46)
先手后手数组取数问题
- 视频:
0:03:15-0:30:00 - 有一个数组,里面数字全是正数,然后两个人依次从数组拿数(数被拿了就相当于从数组中删除,只能从数组头或者数组尾拿数),问拿出数的最大和
暴力递归
- 设计两个函数:先手函数和后手函数,分别在$[L, R]$上取数,代码如下
1 | int s(vector<int>& arr, int L, int R); |
动态规划
- 根据暴力递归,f和s函数生成两个表
- 根据暴力递归主函数调用,确定最终需要的答案
- 左边界不可能大于右边界,所以两个动态规划表下半部分不需要,然后根据暴力递归画图确定填表路径
1 | int winDp(vector<int>& arr) { |
中级提升班1(P49)
绳子覆盖点问题——滑动窗口
- 视频:
0:02:50-0:16:30

思路及代码
思路1:每个数轴上存在的点作为绳子右端点,二分查找
思路2:每个数轴上存在的点作为绳子左端点,滑动窗口
1
2
3
4
5
6
7
8
9
10
11
12
13
14// 滑动窗口
int solution(vector<int>& vec, int lens) {
int L = 0, R = 0;
int n = vec.size();
int ans = -1;
while (R < n) {
while (R < n && vec[R] - vec[L] <= lens) R++;
ans = max(ans, R - L + 1);
L = R;
R++;
}
return ans;
}
捆绑交易最少袋子数量——打表优化
- 视频:
0:16:30-0:44:00
思路及代码
提前筛选:奇数通通不行,偶数才继续试
普通思路:先尝试最大的8个袋子数,然后看剩下的苹果是否能被6整除,如果能,找到并返回,如果不能,减少8个袋子数
改进思路:在本题中,考虑到袋子数量是6和8,那么在剩余的苹果数超过24(最小公倍数),提前停止
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22int minBagBase6(int rest) {
return rest % 6 == 0 ? rest / 6 : -1;
}
int minBags(int apple) {
if (apple < 0 || apple & 1) {
return -1;
}
int bag6 = -1;
int bag8 = apple / 8;
int rest = apple - bag8 * 8;
while (bag8 >= 0 && res < 24) {
int resUse6 = minBagBase6(rest);
if (resUse6 != -1) {
bag6 = resUse6;
break;
}
rest = apple - 8 * (--bag8);
}
return bag6 == -1 ? -1 : bag8 + bag6;
}进阶思路:如果输入和输出都是一个数,那么可以通过打表发现规律
1
2
3
4
5
6
7
8
9int minBagAwesome(int apple) {
if ((apple & 1) != 0) {
return -1;
}
if (apple < 18) {
return apple == 0 ? 0 : (apple == 6 || apple == 8) ? 1 : (apple == 12 || apple == 14 || apple == 16) ? 2 : -1;
}
return (apple - 18) / 8 + 3;
}
补充题:先手后手$4^k$吃草——打表优化
视频:
0:44:00-1:10:10两只动物,先后吃草,没只动物只能吃$4^k,k≥0$数量的草,输入草的数量$N$,问谁赢?(谁先吃完草谁赢)
思路及代码
普通思路:分析普通情况,然后考虑当前的尝试逻辑,先吃1份,看能不能赢,如果不能,尝试吃4份,直到越界或者找到答案
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18string winner1(int n) {
if (n < 5) {
return (n == 0 || n == 2) ? "后手":"先手";
}
// 先手决定吃的草
int base = 1;
while (base <= n) {
// 母过程的先手是子过程的后手
if (winner1(n - base) == "后手") {
return "先手";
}
if (base > n / 4) {
break;
}
base *= 4;
}
return "后手";
}打表:通过尝试多个输入,找到规律
1
2
3
4
5
6string winner2(int n) {
if (n % 5 == 0 || n % 5 == 2) {
return "后手";
}
return "先手";
}
染色的最少次数——预处理(前缀后缀和)
- 视频:
1:10:10-1:28:20

思路及代码
说明:讲的时候可能看错题了,题目要求左R右G,他说的是左G右R,不影响
普通思路:划分为左右两侧,即左侧全为G(如果是R就需要染色),右侧全为R(如果是G就需要染色)

1
2
3
4
5
6
7
8
9
10
11
12
13int minPaint1(string s) {
int N = s.size();
// 枚举左侧部分为L,右侧部分为N-L
for (int L = 0; L <= N; L++) {
if (L == 0) {
// 统计s[0..N-1]有多少个R
}
if (L == N) {
// 统计s[0..N-1]有多少个G
}
// 统计s[0..L]有多少个G + 统计s[L + 1..N - 1]有多少个R
}
}进阶思路:提前处理
s[0..i]上有多少个R(从左往右),提前处理s[i..N-1]上有多少个G(从右往左)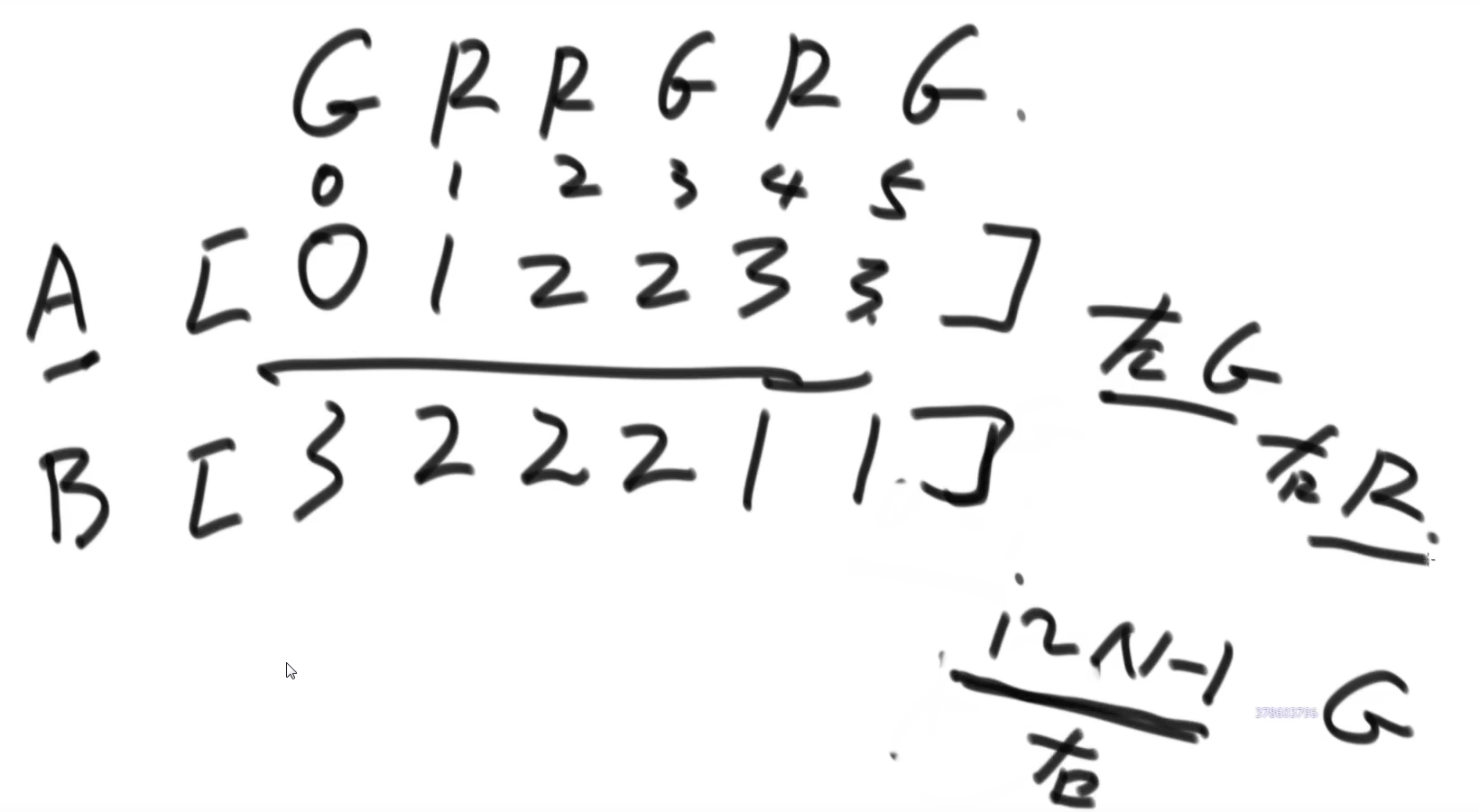
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int minPaint2(string s) {
if (s.size() < 2) return 0;
int n = s.size();
// 统计右侧有多少个R
vector<int> right(n);
right[n - 1] = s[n - 1] == 'R' ? 1 : 0;
for (int i = n - 2; i >= 0; i--) {
right[i] = right[i + 1] + (s[i] == 'R' ? 1 : 0);
}
int res = right[0];
// 统计左侧有多少个G
int left = 0;
for (int i = 0; i < n - 1; i++) {
left += s[i] == 'G' ? 1 : 0;
res = min(res, left + right[i + 1]);
}
return min(res, left + (s[n - 1] == 'G' ? 1 : 0))
}
边框全是1的最大值——预处理
- 视频:
1:30:00-1:55:25

思路及代码
- 正方形:枚举左上角点开始,边长为1开始尝试,直接碰到边界
- 从右往左计算当前点右侧包括自己一共有几个连续的1,right矩阵(和原数组等规模)
- 从下往上计算当前点下侧包括自己一共有几个连续的1,down矩阵(和原数组等规模)
给定随机函数加工出另一个随机函数——位运算
- 视频:
1:55:25-2:06:50

- 以第一题为例:如果随机函数返回1,2返回0,如果随机函数返回3,4返回1,如果是5重新计算,然后通过位运算(3位就可以,因为三位最大可以表示7)计算出等概率返回0~6即可
中级提升班2,3(P48,P50)
不同二叉树结构——递归转dp
- 视频:P48
0:00:30-0:07:26

思路及代码
全局考虑,分左孩子多少种情况,右树多少种情况,最后相乘=>递归
1
2
3
4
5
6
7
8
9
10
11
12int process(int n) {
if (n < 0) return 0;
// 空树
if (n == 0 || n == 1) return 1;
if (n == 2) return 2;
int res = 0;
for (int i = 0; i <= n -1; i++) {
res += process(i) * process(n - i - 1);
}
return res;
}递归改动规
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int dpWay(int n) {
if (n < 0) return 0;
// 空树
if (n == 0 || n == 1) return 1;
vector<int> dp(n + 1);
dp[0] = 1;
// 外层循环表示总节点个数
for (int i = 1; i < n + 1; i++) {
// 表示左树节点个数
for (int j = 0; j < i; j++) {
dp[i] += dp[j] * dp[i - j - 1];
}
}
return dp[n];
}
完整括号串需要添加的括号数量——遍历
- 视频:P48
0:07:26-0:17:00

思路及代码
- 两个变量,
cnt遇到左括号加一,遇到右括号减一,ans如果cnt再减会变成负数,那么加一 - 最终结果即为需要的左括号数量(cnt)加需要的右括号数量(ans)
1 | int needParenthess(string str) { |
差值为k的去重数字对——哈希表
- 视频:P48
0:17:00-0:21:24

思路及代码
- 用哈希表将数组中的元素存储,每次查找哈希表中
k-arr[i]是否存在,存在即加入答案
1 | int getGroups(vector<int>& vec, int k) { |
magic操作:两数组平均值——业务分析
- 视频:P48
0:21:24-结尾+P500:00:00-0:05:00
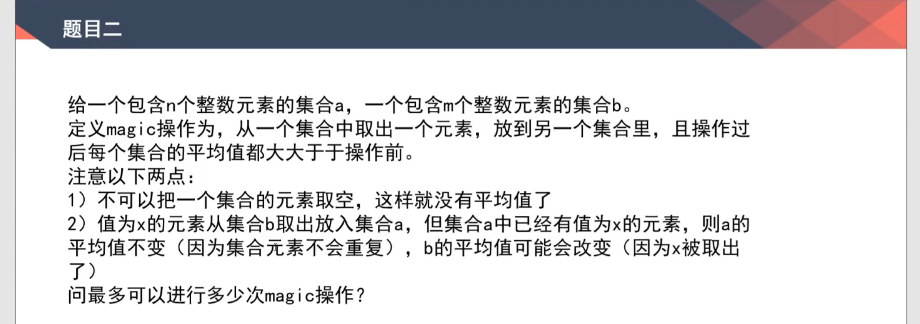
思路及代码
- 分析三种情况
- 集合A和集合B平均值相等:无法进行操作,返回0
- 集合A的平均值大于集合B的平均值:只能在平均值大的集合中拿两个集合平均值之间的数
- 注意:平均值用double存储
1 | double avg(double sum, int size) { |
合法括号的深度——dp
- 视频:P50
0:05:00-0:26:15

思路及代码
考虑以$i$结尾(包含)的位置
- 如果为
(:设为0 - 如果为
):那么看前一个位置i-1的结果的再往前一个位置P- 如果是
(,至少为前一个位置结果+2,并且需要接上p-1位置的答案 - 如果是
),结果为0
- 如果是

- 如果为
1 | int maxLens(string s) { |
使栈中元素升序排序——辅助栈
- 视频:P50
0:26:15-0:30:20

思路及代码
- 准备一个辅助栈,递减栈,两个栈相互倒元素
1 | void sortStack(stack<int>& stk) { |
数字转字符串个数:递归转dp
- 视频:P50
0:30:30-0:46:19

思路及代码
递归:从左往右尝试模型
- 如果当前位置为
0,表示不能匹配,返回0 - 如果当前位置等于字符串长度,说明找到了一种匹配方式,返回1
- 普遍位置:下一次递归从
index+1开始,如果此时index已经到了最后一位,那么直接返回,如果还有下一位,那么判断是否小于27
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19int process(string str, int index) {
if (str.size() < 1) return 0;
// 开头为0,不能进行匹配
if (str[index] == '0') return 0;
// 遍历到结尾,找到一种可能性
if (index == str.size()) return 1;
int res = process(str, index + 1);
// 到了最后一个字符了
if (index == str.size() - 1) {
return res;
}
if (((str[index] - '0') * 10 + str[index + 1] - '0') < 27) {
res += process(str, index + 2);
}
return res;
}- 如果当前位置为
递归转dp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int dpWays(string str) {
if (str.size() < 1) return 0;
int n = str.size();
vector<int> dp(n + 1);
dp[n] = 1;
dp[n - 1] = str[n - 1] == '0' ? 0 : 1;
for (int i = n - 2; i >= 0; i--) {
if (str[i] == '0') {
dp[i] = 0;
} else {
dp[i] = dp[i + 1] + (((str[i] - '0') * 10 + str[i + 1] - '0') < 27 ? dp[i + 2] : 0);
}
}
return dp[0];
}
二叉树,根节点到叶结点的最大路径和——二叉树套路
- 视频:P50
0:46:19-1:00:45

思路及代码
- 二叉树套路题,找左右两个孩子要答案
1 | int process(TreeNode* root) { |
二维矩阵搜索(每行每列升序)——右上角查找
- 视频:P50
1:01:15-1:04:45

思路及代码
- 从右上角开始进行二分查找
1 | bool searchMatrix(vector<vector<int>>& matrix, int target) { |
补充题:求含有连续1最多的行——右上角查找
视频:P50
1:04:45-1:10:40每一行数,0一定在1的左边,要求找到1最多的行
思路及代码
- 从右上角开始,如果是1往左走,如果是0往下一行一走,继续这个套路
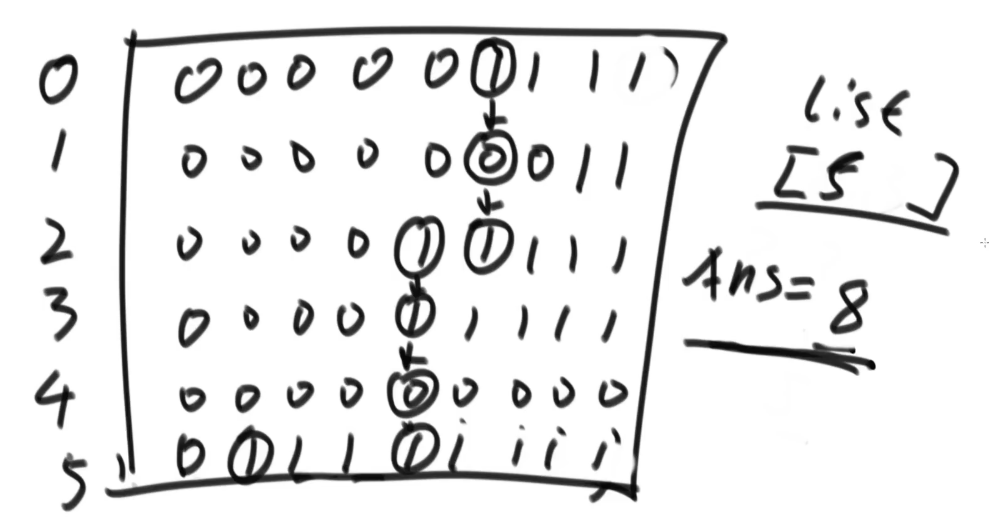
1 | int countOne(vector<vector<int>>& arr) { |
中级提升班4(P51)
洗衣机问题——分析当前位置
- 视频:
0:01:14-0:25:15

思路及代码
- 考虑当前位置
i,那么我可以知道- 左侧目前有多少衣服,实际需要多少衣服
- 右侧目前有多少衣服,实际需要多少衣服
- 假设需要衣服为负数,扔出衣服为正数
- 四种情况
- 总和不能被整除,肯定不符合,返回0
- 左右两侧都接收衣服(都为负数):那么肯定是当前位置
i往两边扔,由于一次只能扔一件,所以需要abs(left) + abs(right) - 左右两侧都扔出衣服(都为正数):那么只有当前位置
i需要接收衣服,接收能力没有限制,所以共需要max(abs(left), abs(right)) - 一侧扔一侧接收(一正一负):那么中间需要操作的次数同都为正数的情况,因为可以在接收的同时扔出衣服
- 那么每个位置最高的瓶颈即为答案
1 | int findMinMoves(vector<int>& machines) { |
螺旋打印矩阵——全局考虑(左上角右下角)
- 视频:
0:26:30-0:33:10

思路及代码
- 打印左上角和右下角区间内数字,三种情况
- 只有一列,既打头又打尾
- 只有一行,既打头又打
- 普遍情况:先右再下再左再上,打头不打尾
1 | class Solution { |
矩阵旋转——宏观调度(考虑几个位置)
- 视频:
0:33:10-0:52:20

思路及代码
- 考虑四个角的位置相互转
1 | class Solution { |
zigzag——宏观调度
- 视频:
0:52:24-0:59:40

思路及代码
- 首先用两个点(A, B)标记起始位置
- A只往右走,走到不能走了往下走
- B只往下走,走到不能走了往右走
- 每次打印两个点之间的内容
- 用一个变量控制打印顺序(A->B or B->A)
- 注意:A先查行再查列,B先查列再查行
1 | vector<int> ans; |
最少拼接次数*
- 视频:
1:04:00-1:22:05

字符串数组TopK*
- 视频:
1:22:05-1:31:20

补充题:自定义堆结构——可变的TopK*
- 视频:
1:31:20-2:13:19

中级提升班5(P52)
实现栈:能够返回栈中最小元素*
- 视频:
0:03:05-0:06:30

栈实现队列 & 队列实现栈*
- 视频:
0:06:30-0:15:05

二维数组最小路径和——动态规划空间压缩技巧*
- 视频:
0:15:05-0:36:00

一维接雨水*
- 视频:
0:36:00-0:55:50

最大的左右部分最大值之差的绝对值*
- 视频:
0:55:50-1:03:00

字符串是否互为旋转词*
- 视频:
1:03:00-1:07:15

补充题:咖啡杯问题*
- 视频:
1:07:15-1:49:15

相邻数字是4的倍数*
- 视频:
1:49:15-2:00:50

中级提升班6(P53)
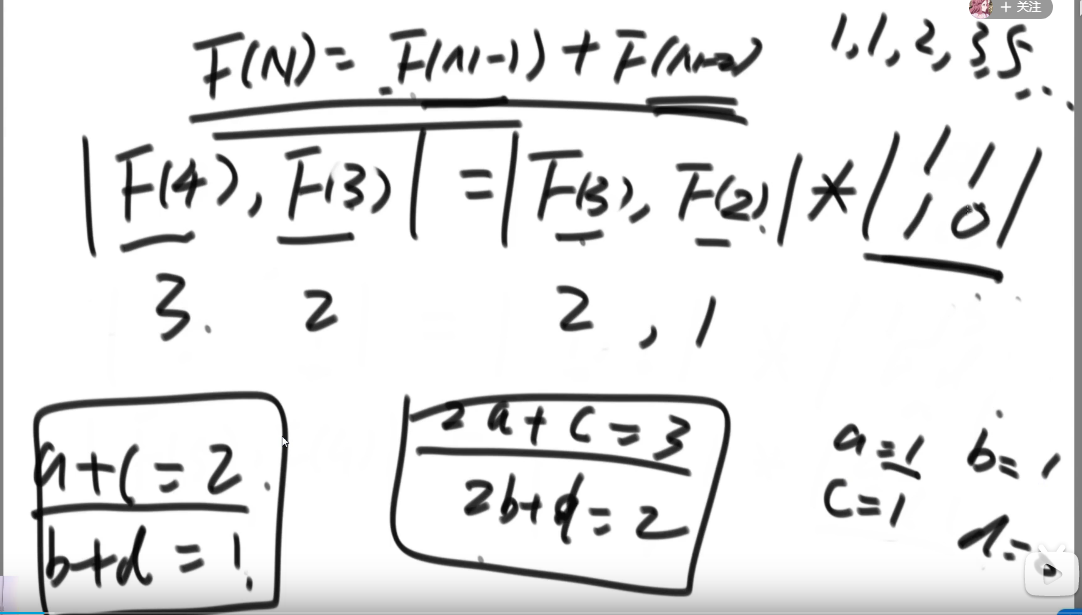
斐波那契数列套题——行列式*
- 视频:
0:01:40-0:39:30
补充题:牛生产问题*
- 视频:
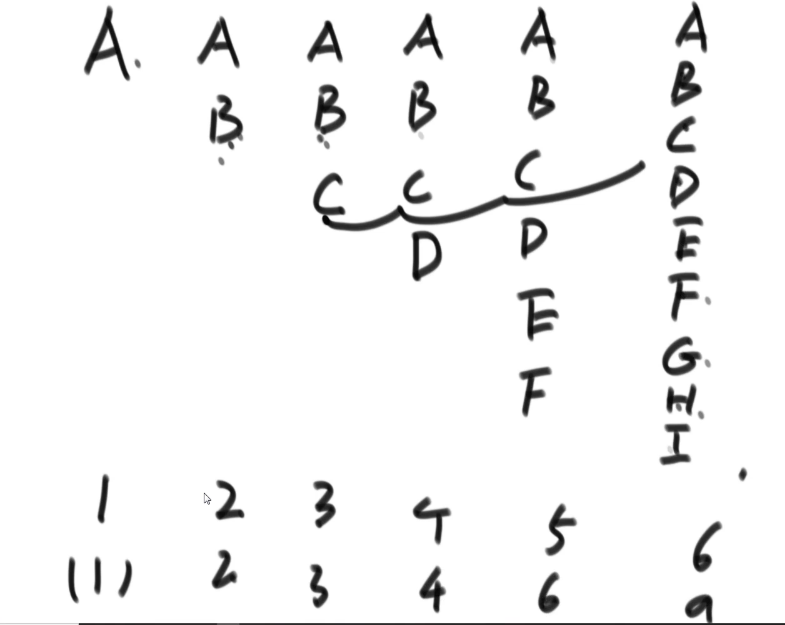
0:39:30-0:47:30 - 描述:母年一年可以生一只,三年后成熟可以生产,问n年后多少年。假设牛不会死
补充题:兔生产问题*
- 视频:
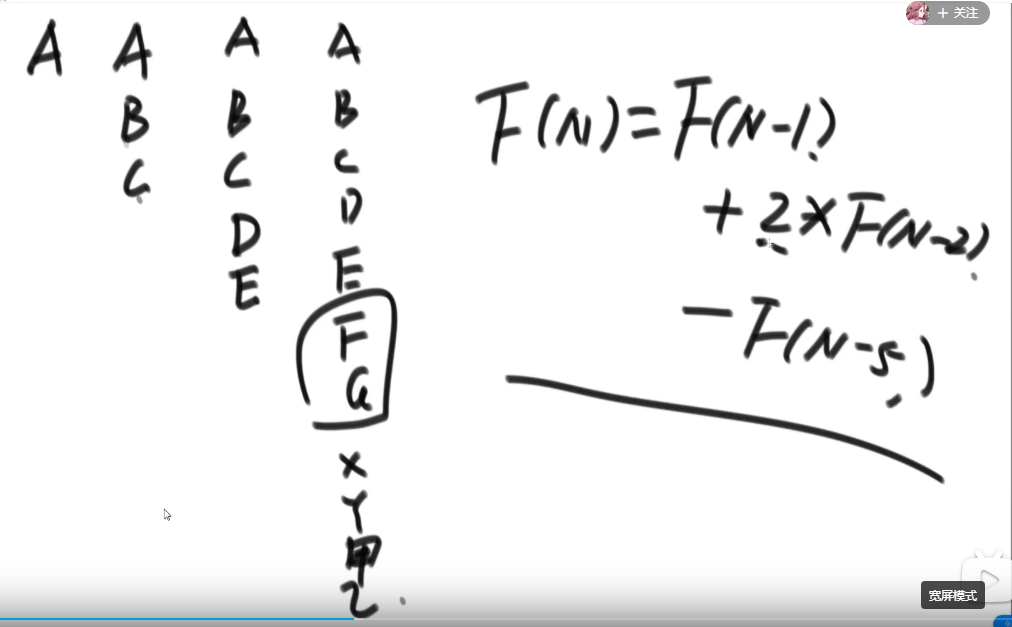
0:47:30-0:51:30 - 描述:和上一题差不多,修改一点点。母年一年可以生两只,两年后成熟可以生产,问n年后多少年。兔子五年后会死
符合要求的字符串:出现0的左边必有1*
- 视频:
0:54:10-1:04:20

去掉木棍,使得任意三根不能组成三角形*
- 视频:
1:04:20-1:11:00
背包问题:零食放法*
- 视频:
1:12:00-1:19:00

报酬与能力:找工作*
- 视频:
1:19:00-1:30:40

字符串转日常书写整数*
- 视频:
1:30:40-1:56:20

中级提升班7(P54)
子目录打印问题*
- 视频:
0:01:10-0:20:00
搜索二叉树转有序双向链表*
- 视频:
0:20:30-0:28:10

思路及代码
- 递归:解决以X为头的整颗树
1 | vector<Node*> process(Node* node) { |
最大搜索二叉子树的节点个数*
- 视频:
0:30:50-1:31:20

打分——最长连续子数组和*
- 视频:
1:34:10-1:54:35

最大子矩阵的和*
- 视频:
1:54:35-2:08:00

中级提升班8(P55)
最少路灯数*
- 视频:
0:01:40-0:24:10

前序中序数组生成后序数组*
- 视频:
0:24:10-0:46:35

数字的中/英文表达*
- 视频:
0:46:35-0:58:55

完全二叉树的节点个数*
- 视频:
0:59:15-1:19:45

最长上升子序列*
- 视频:
1:19:45-1:54:00

判断区间内能被3整除的个数*
- 视频:
1:56:00-2:03:35

中级提升班9(P56)
找出未出现在数组中的数
- 视频:
0:01:30-0:09:15

主播晋级*
- 视频:
0:09:25-0:33:35

参与活动的最大奖励*
- 视频:
0:37:50-0:58:40

字符组成达标结果的数量*
- 视频:
1:00:00-1:27:50

没有重复字符的最长子串*
- 视频:
1:28:40-1:36:40

编辑距离问题*
- 视频:
1:40:00-2:01:10

删除多余字符使得字典序最小*
- 视频:
2:02:00-2:14:50

中级提升班10(P57)
字符串排序后的位置*
- 其他都在9讲过
- 视频:
1:37:20-2:00:00

高级进阶班1(P58)
相邻两数最大差值
- 视频:
0:01:30-0:31:50
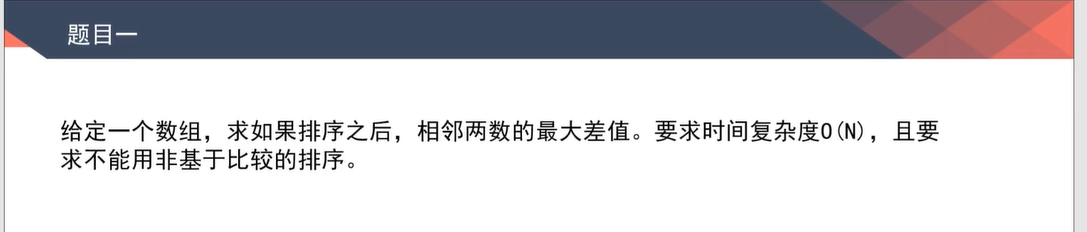
思路及代码
- 假设数组中有N个数,准备N + 1个桶(为了舍弃可能性:最大差值必不可能在同一个桶内)
- 第一次遍历,找到全局最大值mx和最小值mi
- 第二次遍历,确定每个桶的最大值,最小值以及桶内是否有数,通过公式$(x - mi) * N / (mx - mi)$得到每个数应该在的桶
- 第三次遍历,比较相邻桶的差值,找到答案
1 | int bucket(int num, int n, int mi, int mx) { |
高级进阶班5(P62)
字符串公式计算
- 视频:
1:02:30-1:04:50

不带括号(只考虑正数)
不带括号,表明不需要考虑额外的优先级,即只有
+-*/,因此此部分不处理负数核心:双端开口栈(
deque)遍历字符串,用一个数字记录当前扫过的数字字符,遇到运算符就考虑入栈,如果栈顶是
+-,直接入栈,如果栈顶是*/,弹出计算结果,再入栈最后计算栈中所有结果
是下面的简化版本,代码略
带括号-递归(包打一切)
- 带括号,表明需要考虑额外的优先级,包打一切
- 核心:双端开口栈(
deque) - 遍历字符串,当还有字符且字符不为
)时,考虑三种情况- 当前字符是数字字符,累加到num上
- 当前字符非
(,即可能是运算符,或者)时,进行一次结算,即将num和当前字符入deque - 当前字符是
(,递归去处理后面的情况,并更新此时的num和新下标 - 最后将
num将加入deque
- 返回此处的结果与下次开始的坐标
1 |
|
带括号-迭代(未考虑乘除)
- 力扣评论区优秀的解法
1 | class Solution { |
高级进阶班11(P68)
完美洗牌问题,{L1, L2, …Ln, R1. R2,…Rn}=>{R1,L1,R2,L2,…Rn,Ln}
- 视频:
0:29:00-1:04:50

- 要求时间复杂度$O(nlog_3n)$和空间复杂度$O(1)$
思路及代码
假设下标从1开始,数组长度为$2n$,那么位于左半区的$i$位置最终要去的位置为$2i$,位于右半区的$i$位置最终要去的位置为$(i-n)*2-1$
不同圈
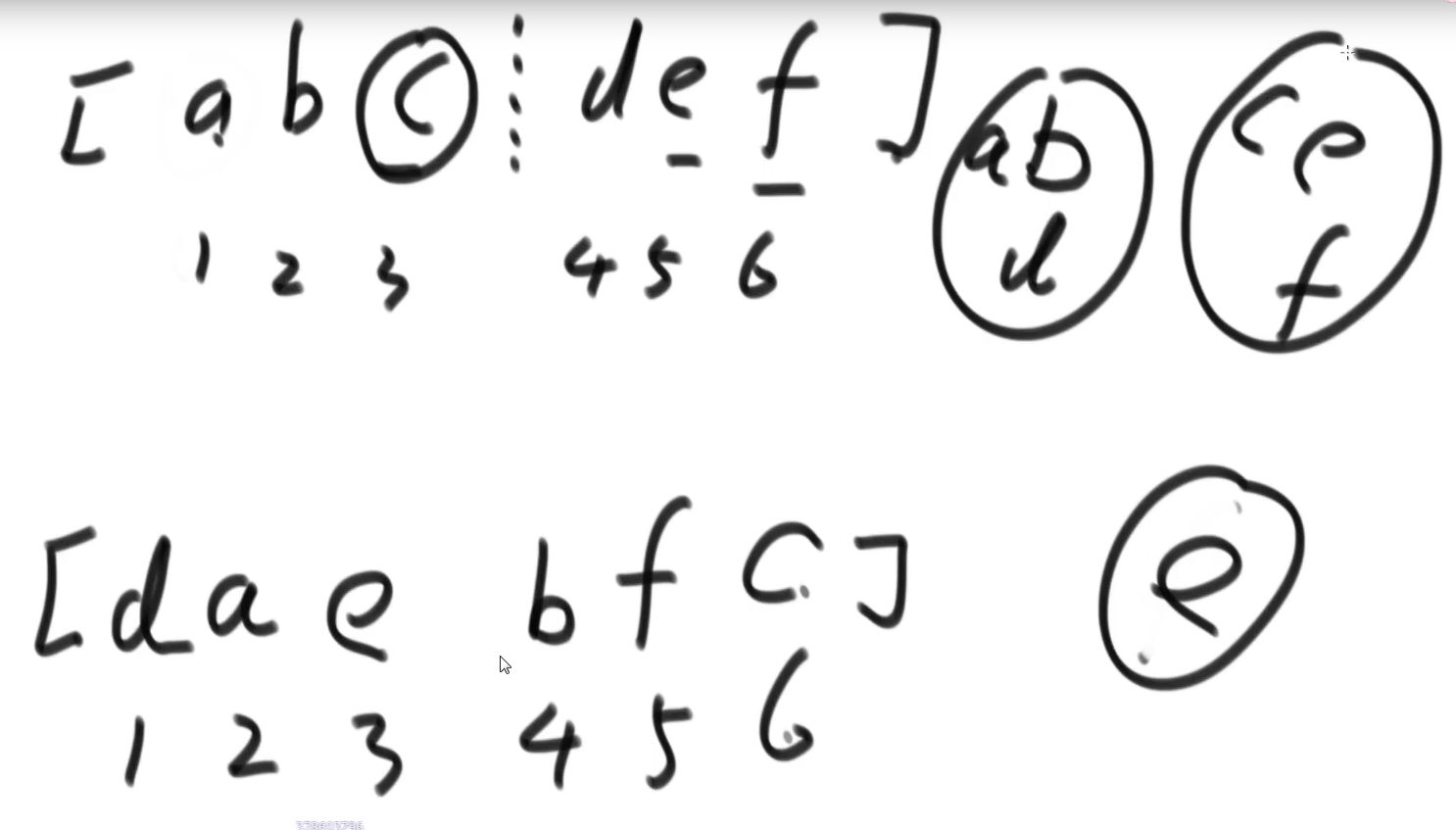
利用
完美洗牌问题结论:当整个数组长度$M$满足$M=3^k-1,k≥1$时,不同圈的出发位置为$[1,3,9,3^{k-1}]$补充:为什么需要进行三次逆序?实现实际长度不等于$3^k-1$的数组,即先解决最接近$3^k-1$的子数组(左右部分平移逆序,时间复杂度O(k),k为数组长度,空间复杂度O(1))
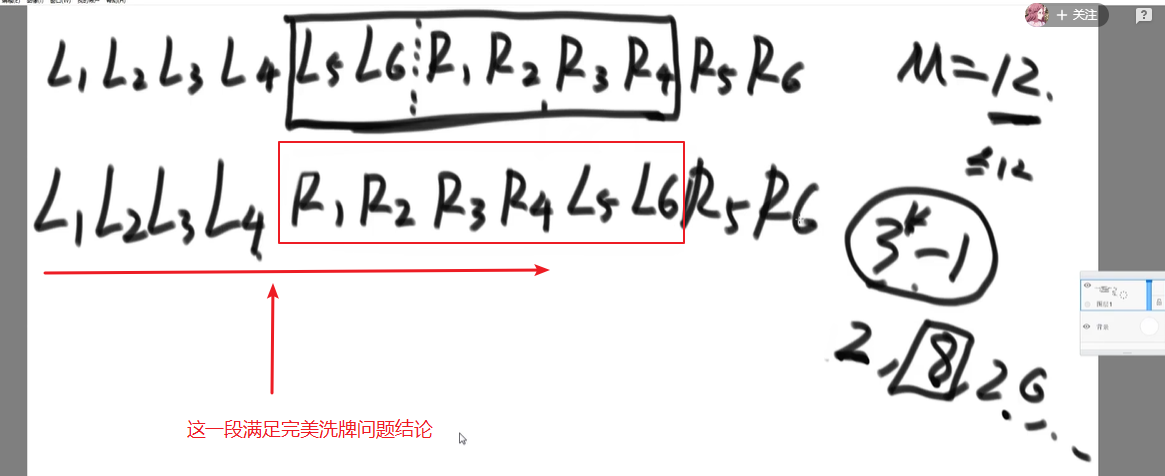
1 | // 数组总长度len,调整前位置为i,返回调整后的位置 |
扩展
给定一个数组,要求调整之后数组相邻元素满足:<=,>=,<=一直下去
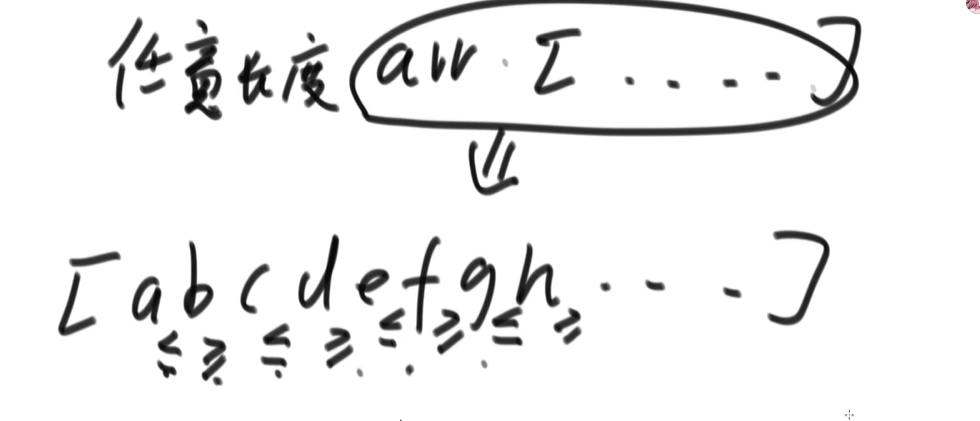
思路:使用堆排进行排序(时间足够快,空间复杂度小)
长度为偶数,然后使用完美洗牌算法进行排序即可

长度为奇数,剔除第一个(排序之后最小的数)

最大线段重叠问题
- 视频:
1:31:40-1:57:55 - 有个二维数组,每一个位置代表一个线段的起始和结尾位置,求最大重叠的线段数量(压点不算,即[1,2],[2,3]结果是1),如{ {2, 5},{1, 9},{3, 10},{6, 8},{2, 4} }最长重叠包含的线段有四条(除了6,8)
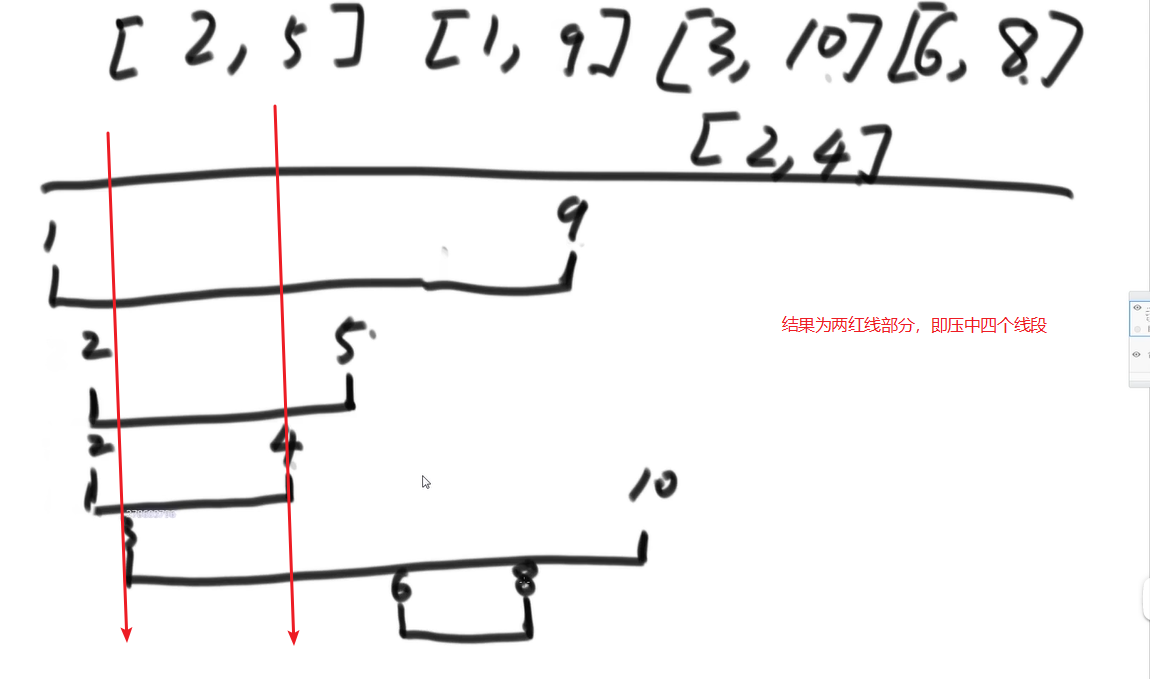
思路及代码
- 以起点升序排序
- 有序表存当前位置结尾(删除不符合要求的数据)
1 | /* |
扩展:最大矩形重叠问题*
- 线段问题扩展为矩形重叠问题
- 思路
将每一个矩形,根据底边升序排序
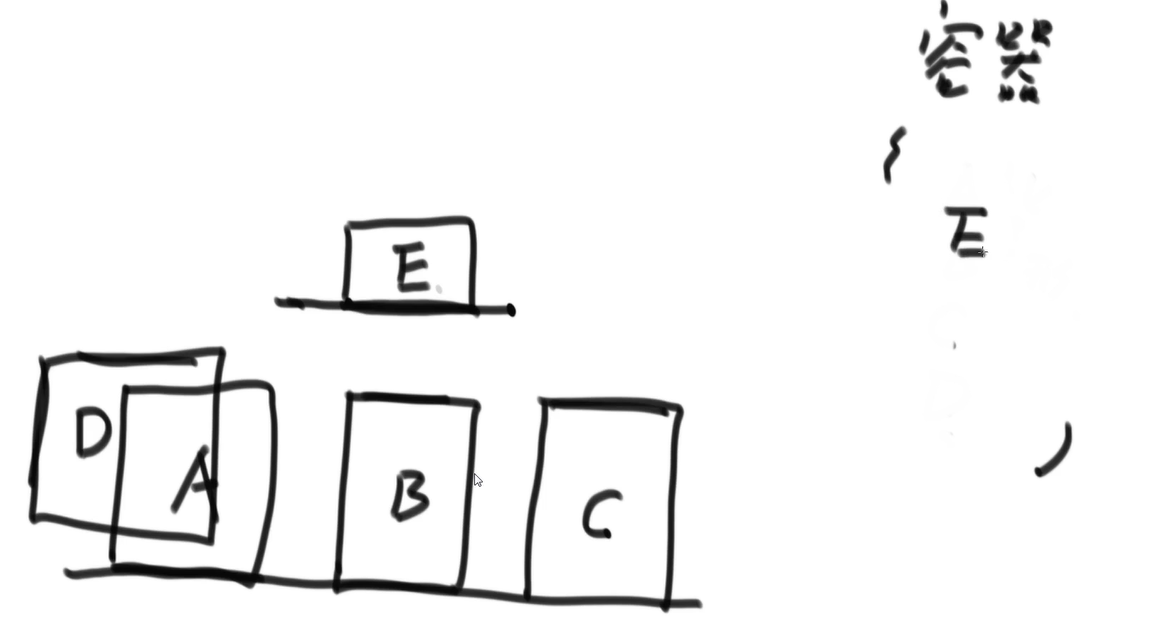
先处理在下方的矩形,准备一个容器,如果当前遍历到的矩形X的底边,没有超过容器中最高矩形的顶边,加入=>换句话说,删除所有顶边低于当前X的矩形,求此次答案
ABCD时,如下
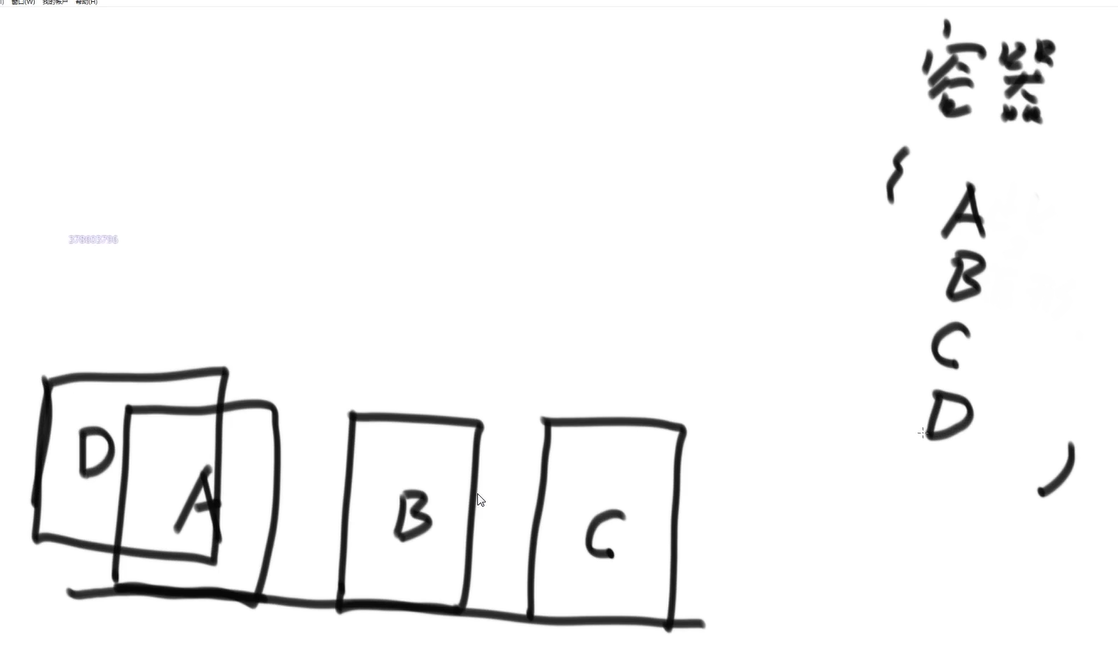
加入E后,如下
变换成线段重叠问题求解





